This time we get into a brief overview of beer brewing from grain, including a bit about malting, mashing, boiling, and fermenting, along with the critical role of groundwater pH in driving the invention of the major beer styles.
Food Class podcast

All of the posts here with a brief text and an audio attachment are part of a podcast for my summer ‘Food’ class. I’m using my WordPress site here to host these entries as a podcast, which you can subscribe to in Apple Podcasts or directly by the RSS feed, or just open the category page for ‘foodclass’ and listen in the browser.
Pitfalls of real-time, remote teaching
Daniel Stanford, writing back in March about videoconferencing as a way to re-create the classroom experience:
We like the idea of being able to see and hear our students while interacting with them in real time just like we do when teaching face to face. But there are two key factors that make this approach problematic.
Daniel Stanford, Director of Faculty Development and Technology Innovation at DePaul University’s Center for Teaching and Learning
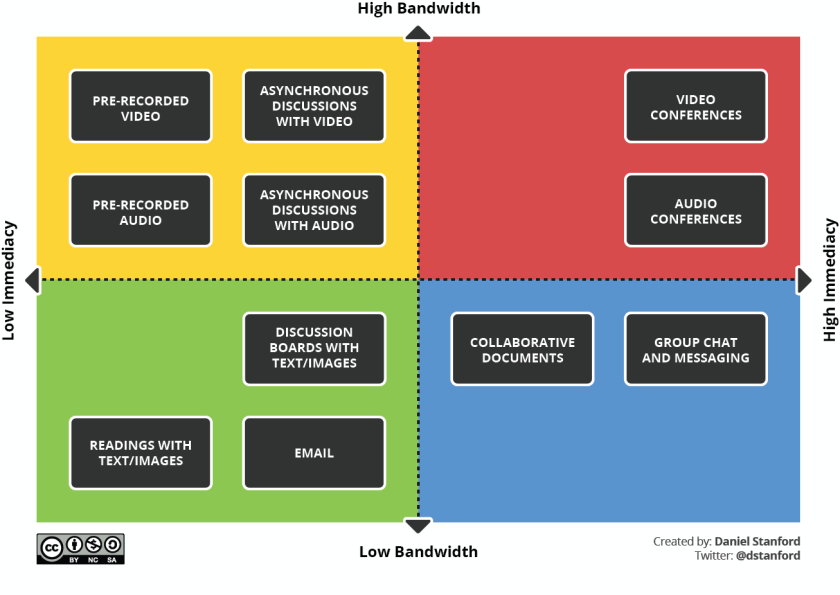
Stanford goes on to describe some of the pitfalls of holding class in real-time but remotely. He does a great job of plotting the various tools along the axes of immediacy and bandwidth. Worth a read as we debrief and take stock of the spring and prepare for fall classes.
Wheat
Wheat was one of the first crops to be domesticated and is one of the most important food crops for humans today. Let’s talk a little bit about where modern wheat came from and how it’s changed from its wild ancestors.
Maize
Maize (or corn) is one of the most productive crop plants, having been domesticated from a humble, branching grass in southern Mexico with just a few seeds per branch into a powerhouse of productivity. Hear more about where maize comes from, where it’s used, and how it does what it does in this episode.
Seeds
The vast majority of human calories comes from seeds. In this episode we hear about the 3 main parts of every seed and where those calories come from.
Apples
Apples were probably the first tree crop to be domesticated, with evidence suggesting this happened over 8000 years ago in modern-day Kazakhstan. In this episode we also learn about self-incompatibility and grafting, two ideas that allow us to grow the kinds of apples we love to eat.
Chocolate
Chocolate is delicious, with over 600 volatile flavor compounds and a smooth, creamy feel in the mouth that melts exactly at body temperature. Let’s talk a little bit about where chocolate comes from and what makes it so special.
Coffee
If there’s a single plant product that I could not live without, it might be coffee. Let’s take a quick look at where this magical drink comes from and some of the factors that make it what it is.
Fruit Types
The wide variety of fruits we eat all develop from certain parts of the parent plant. While many fruits develop from the ovary wall, some of the most common fruits we eat do not! Listen here to find out more about the types of fruits and where they come from on the plant.
